組織の業務や、顧客へのサービス提供へ大きな影響を与えかねない「システム障害」は、原因や発生事象の観点で様々な種類が存在します。
障害の発生を未然に防ぎ、いざ発生してしまった時の被害を最小限に抑えるためには、平時から対応フローの整備、代替システムの準備といった適切な対応を決めておく必要があります。
本記事では、システム障害の種類や対応フロー、事前準備など関連知識を網羅的に解説しています。
システム障害とは?
「システム障害」とは、社内のシステムや外部システム、自社が顧客へ提供しているシステムなど、何らかのITシステムにおいて、構成する機材やソフトウェア、通信回線といった要素に問題が発生し、正常な稼働を維持できなくなる状況のことを指します。
システム障害が発生すると「業務に必要な機能や通信を利用できなくなる」「保存していたデータが消失する」というようなトラブルを引き起こします。さらに障害の度合いが深刻なケースでは、利用者や管理者の操作を一切受け付けなくなったり、システムが完全停止してしまったり、正常な状態へ復旧するまで場合によっては何日間と要することもあるのです。
深刻なシステム障害は自社業務のみならず、関係各社や顧客にまで影響を及ぼすことが予想されます。また、事業存続の危機にまでつながりかねないため、事前にしっかりとシステム障害を未然に防ぐ対策を行うこと、障害発生時の対応フローを策定しておくことが重要です。
サーバーやネットワークなど様々なシステムの障害について、下記の関連記事も併せてご覧ください。
▼サーバー障害の主な原因は? 対処と回避策について徹底解説
▼なぜネットワーク障害は起きるのか? 原因を徹底解説

システム障害の主な原因
システム障害への対策を講じるためには、システム障害の原因となる事象を理解することが必要です。
システム障害の原因には、大きく分けて「外部要因」と「内部要因」があります。
次項より、それぞれを詳しく解説します。
外部要因
外部要因とは、社内システムの利用状況や環境を問わず、半ば不可抗力的に外部からの影響をシステムが受けてしまうことをいいます。
外部要因として、以下の3つが該当します。
- 外部からの攻撃
- アクセス集中
- 自然災害
1.外部からの攻撃
外部からの攻撃では主に、外部の第三者から悪意をもって社内システムを攻撃されます。IT分野における外部からのシステム攻撃は「サイバー攻撃」とも呼称します。
サイバー攻撃は、目的や手口、標的が多岐にわたりますが、代表的なものは以下の通りです。
- マルウェア
マルウェアは、組織が運用しているシステム・サーバー・PC端末などを標的とし、不正かつ有害なソフトウェアを侵入させ、悪用したり害を与えたりする悪意あるソフトウェアの総称です。
マルウェアの侵入経路としては「インターネット上で有益なソフトウェアを装って配布」「メールの添付ファイル」「メールのソース自体に巧妙に動作プログラムが仕組まれている」「社内で利用しているストレージに入り込んでいる」など、様々な手口があります。 - SQLインジェクション
データベースが標的とされるサイバー攻撃です。データベース上で一般的に用いられるSQLコマンドを悪用して対象のデータベースに入り込み、内部に保存されている情報の搾取・改ざん、データの削除を行います。 - パスワードリスト攻撃
ユーザーのID・パスワードを攻撃者が何らかの方法で入手し、クラウドサービスや業務システムなどへ不正ログインします。攻撃者はログイン後、システム内で悪意をもって操作やデータ改ざん、削除などを行います。 - 標的型攻撃
標的型攻撃では、あらかじめ特定の組織・団体などを標的として設定し、その組織・団体の関係機関や取引先などを装って接触します。
目的を果たすため、標的となる関係機関や取引先などを装って長期間にわたり、計画的に接触します。
例えば、メールにいきなりマルウェアを添付するのではなく、問題のないメールのやりとりを何度か重ね、相手を信用させた上で攻撃を開始する、といった手口を使うようです。 - ゼロデイ攻撃
組織が利用している業務システムやソフトウェアにおいて、しばしばセキュリティホールとなるようなプログラム上の欠陥が見つかることでしょう。この場合、提供ベンダーはその欠陥に対し、迅速に対応を行ってアップデートを配布するという状況がありますが、ゼロデイ攻撃では、この「欠陥の発覚」から「提供ベンダーの対応」の間の短い期間にうちに、そのぜい弱性を利用して攻撃を行うのです。 - バッファオーバーフロー攻撃
バッファオーバーフロー攻撃は、サーバー・PCの処理能力を超えるほどの大量データや、無限の処理が繰り返される悪意のあるプログラムなどを送りこみ、対象のシステムのバッファオーバーフロー(メモリ内のバッファ許容量を超えた過剰な処理を行ってしまう状態)を引き起こす攻撃です。
バッファオーバーフローが発生したシステムは、異常終了してしまう他、攻撃者が任意のコマンドをいつでも実行できる状態になってしまう事象もあります。 - DoS攻撃
DoS(Denial Of Service)攻撃は、様々な手段で対象のシステムへ過負荷を与えることで、システム上で稼働しているサービスを停止させる攻撃です。
DoS攻撃に用いられる細かな手段としては、メールボム攻撃(大量のメールを送りつける)やF5攻撃(悪意のあるWebページを介し、PC側にページ更新機能の「F5キー」を連続して何度も押しているような状態を発生させ、PCに負荷を与える)などがあります。 - DDoS攻撃
DDoS(Distributed Denial Of Service)攻撃は、前述のDoS攻撃の発展型ともいえます。
攻撃者は、PCやインターネット上に存在しているルーター・ネットワークカメラといったIoT機器を踏み台とした上で、標的に対して分散したDoS攻撃を行います。DDoS攻撃では、分散された発信源から一度に大規模な攻撃が到着してしまうため、システムへの影響がより甚大となります。また、攻撃者の絞り込みやIPアドレスによるブロック処置などが困難となるようです。
2.アクセス集中
アクセスの集中とは、大量のアクセスを受け、サーバー側に負担がかかり、サーバーの対応が追い付かない状況のことを指します。また、ソフトウェアの誤動作や停止、ハードウェアの熱暴走や故障などを引き起こす可能性があります。
前項で解説した、悪意のある攻撃によってアクセスの集中が発生するケースもありますが、ユーザーの自然な行動でアクセスの集中を引き起こすこともあります。
例えば、自社のサービスとして「顧客に対して期間限定・先着順のサービスや商品を告知した」「数量限定で大幅値下げという販売施策を打った」といった特別なキャンペーンを行った際に、ユーザーのアクセスが集中する可能性は非常に高くなるでしょう。
許容量を超えた大量のアクセスが自社のWebサイトや関連システム(Webサイトと連動するアプリケーションサーバーなど)に集中した場合、システムの誤動作や異常終了を招くことが予想されます。
3.自然災害
自然災害は、人為的に避けることのできない、どのような環境でも起こり得る事象ですが、自然災害もまたシステム障害の外部要因のひとつです。
システムやサーバーをはじめ、電子機器は地震による大きな振動や雷による過電流・過電圧に弱く、また深刻な水害によっても壊滅的なダメージを受けやすいものです。
日本は世界的に見ても自然災害が多い国のため、事前の対策は必須となるでしょう。
内部要因
次に、社内のシステム利用状況や操作状況などを発端とする内部要因について解説します。
内部要因として、以下の3つが挙げられます。
- ヒューマンエラー
- ソフトウェア障害
- ハードウェア障害
1.ヒューマンエラー
ヒューマンエラーは業務では付き物ですが、システム障害の例としては「従業員や顧客がシステム上で誤った操作をしてしまった」「エンジニアが重大な設定ミスをしてしまった」といった操作上のエラーが多く原因となっています。
また、外部要因として紹介した「マルウェアが忍び込んでいるファイルが添付されたメールを、社員が十分に確認せず、安易に添付ファイルを開いてしまう」ということも、セキュリティ意識の低さもヒューマンエラーに該当するでしょう。
2.ソフトウェア障害
ソフトウェア障害とは、業務に利用している様々なソフトウェアに、元々何らかの欠陥があり、誤動作を起こしてしまったり、また最新のバージョンへ更新していなかったことにより不具合が起こったりすることをいいます。
ソフトウェアをクラウドサービスで使用している場合、ソフトウェア障害が発生しても、一般的に障害対応はクラウドサービス事業者によって行われるため、基本的には自社でできることは少なく、事業者側の復旧を待つしか方法はないようです。
3.ハードウェア障害
ハードウェア障害は、機器類の経年劣化やアクセスの集中、攻撃による過負荷など様々な理由によって、システムやサーバーが機械的に故障してしまうことを指します。
例えば、サーバーを稼働させているコンピューターでは、内部的なハードウェアとしてCPU、メモリ、ハードディスクやマザーボード、電源ボックスなどがあります。
このいずれかが故障したのに加え、システムを二重化・冗長化といった対策を行っていない場合には、正常な動作を行えなくなる可能性が非常に高くなります。
システム障害が発生した際の対応
システム障害が発生した場合には、あらかじめ策定しておいたフローを基に、適切かつ迅速な対応を行うことが重要です。
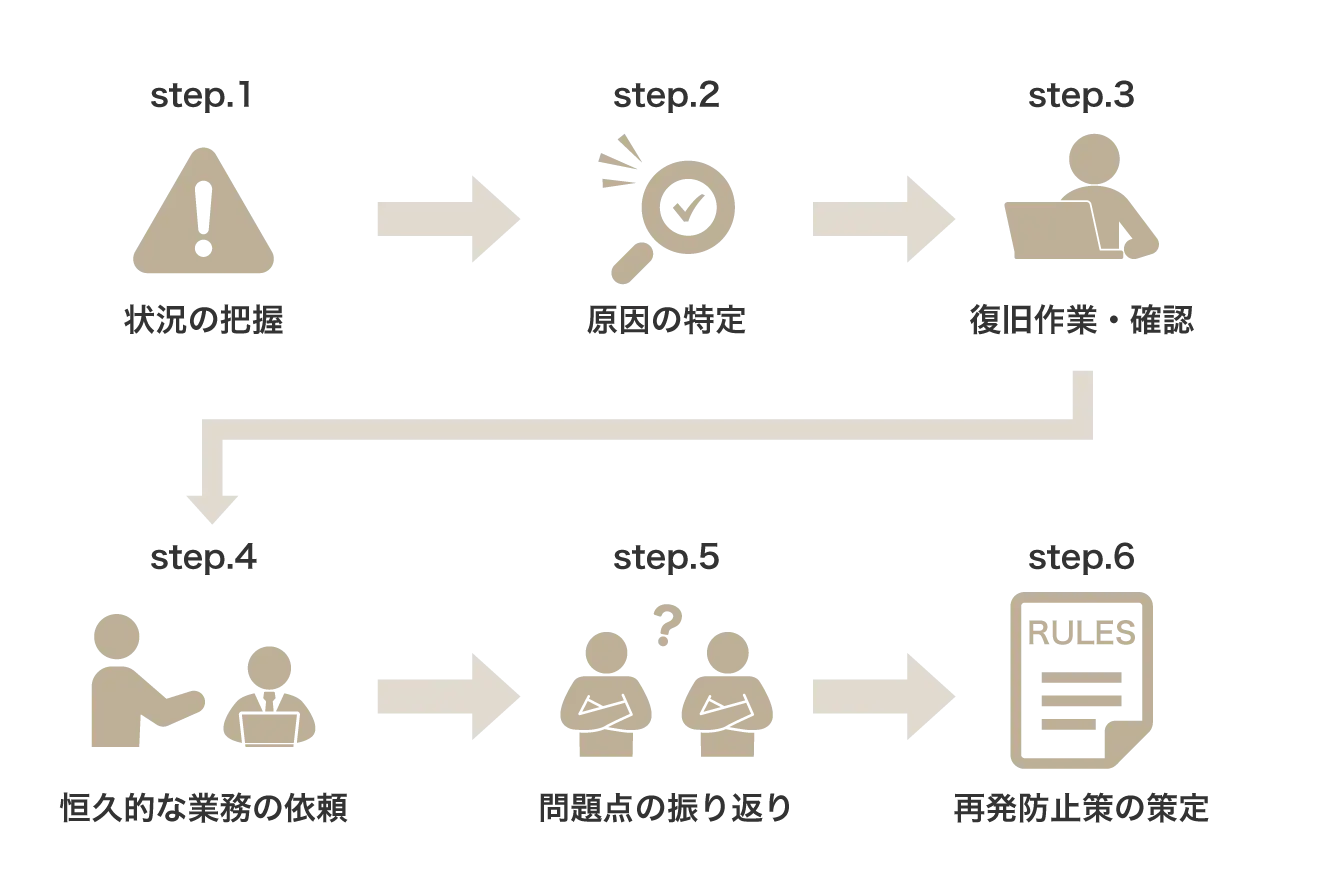
システム障害発生時の大まかな対応フローをまとめると、おおむね以下のような流れになります。
- 状態を把握する
- 原因を特定する
- 復旧作業・復旧確認
- 恒久的な修理や修正を担当者に依頼する
- 問題点の振り返り
- 再発防止策の策定
システム障害やセキュリティインシデントを含む、ITシステムにおけるトラブル発生時の対応フローについて、こちらの記事も併せてご覧ください。
▼セキュリティインシデントの対応フローや参考となるガイドラインを解説
▼「インシデント」と「障害」は異なる? ITシステム運用における定義の違いや対応フローを解説
システム障害への備え
システム障害が発生してしまった場合の対応フローを正しくスムーズに行うためには、以下のような準備を平常時から整えておくことが重要です。
- 障害の予兆を見抜く体制の準備
- 障害処理を行うための方針の設定
- 障害の原因を特定(切り分け)するためのフローの整備
- 状況ごとに適切な連絡先の準備
- ヒューマンエラーを防止・低減させるための施策
- サーバーをはじめとする重要なシステムの予備・バックアップの用意
- 負荷分散の実施
- 障害解決後、社内へナレッジの共有
次項より、詳細を紹介します。
1.障害の予兆を見抜く体制の準備
システム障害となる原因は多様な種類がありますが、それらの一部には致命的な障害発生に至る予兆段階が存在します。
例えば、ハードウェアの故障であれば「以前に比べて動作がスムーズではなくなった、処理に時間がかかる」といった事象が予兆となり、「機器が異常な熱を持っている」場合もハードウェアの故障を予兆しています。
ハードウェアの故障の予兆を拾い上げるためには、定期点検の仕組みを整備し実行することが有効です。その他のケースも含め、セキュリティ担当者が予兆のリストを入念な洗い出しの上で作成し、システム利用者へ周知を行ったり、予兆が見られた際のエスカレーションルートを策定したりすることも対策として挙げられます。
2.障害処理を行うための方針の設定
システム障害により事業を停止させないためにも、代替手段への切り替えを行える環境を整えましょう。
また、原因究明と復旧作業を並行して速やかに進めるためには、平時から代替機材の準備や非常時の対応マニュアル・行動計画の策定、模擬的な環境による訓練などを行っておくことが重要です。
3.障害の原因を特定(切り分け)するためのフローの整備
障害発生時の原因切り分けを速やかに行うためには、あらかじめ想定される様々な原因をリストアップしましょう。
リストアップを基に、それらへ最短で正確にたどりつくためのフローを整備し、従業員に定着させることが大切です。
4.状況ごとに適切な連絡先の準備
障害の原因が特定できたら、ハードウェアやソフトウェアなどそれぞれに対応する情報システム部門や、機器ごとのサポート部署などへ速やかに連絡を入れる必要があります。
発生した障害の原因によって連絡先が複数ある場合、どこに連絡すればよいかわかりやすく連絡リストの作成をおすすめします。
5.ヒューマンエラーを防止・低減させるための施策
ヒューマンエラーは、突発的にミスだけが原因ではありません。その前段階として「操作上の注意を怠る傾向が日常的に見られた」「正しい操作に関するレクチャーや、誤操作が引き起こす問題の重大性についての周知が徹底できていなかった」などの原因も考えられます。
平時から、ヒューマンエラーの発生の可能性を最大限抑えられるように、教育や周知を徹底することが大切です。
6.サーバーをはじめとする重要なシステムの予備・バックアップの用意
システム障害が発生してしまった場合でも、当該システムや関連するデータの冗長化・二重化などを行っておけば、一定以上の業務遂行・サービス提供を継続できます。
特に、自社業務や自社サービスの基幹となるシステム・機器・ソフトウェア・データなどについては、予備やバックアップを常に準備しておきましょう。
7.負荷分散の実施
多くの従業員や顧客が同時にアクセスすることが予想されるシステムやサーバーについては、負荷分散の仕組みを導入するとよいでしょう。
「予備サーバーを整備して処理を分散させる」「必要に応じて可能な部分はクラウドサービスにて稼働させる」といった方法を日常的に行うことで、負荷の一点集中を回避できます。
8.障害解決後、社内へナレッジの共有
システム障害の復旧対応を一通り完了できた後は、当該事象の内容や対応結果、起こった影響などについてとりまとめ、ナレッジとして社内へ共有します。
障害に関する情報の共有は、システム運用やセキュリティへの意識を高めることにもつながります。また、同様の事象が再度起こりそうな状況になった際に、予兆へ気付いたり対応事例に基づいた正しい処理が行えたりと、今後のシステム障害への対策を確固たるものとするでしょう。
システム障害に備えたマニュアルづくり
システム障害に備えたマニュアルを整備する際には、特に「監視項目(障害発生箇所となり得る細かな対象)ごとの個別の障害対応マニュアル」を準備しておくことが重要です。
その点も含め、ポイントをご紹介します。
基本方針の明文化
マニュアルの冒頭では、まず障害対応における基本方針を明文化します。
- 障害の予兆を検出・検知するためにどのような監視を設定するか
- システム監視・運用スタッフのチーム分けや配置
- 障害検知時の通知手順
- 初動対応チームのアサインと役割分担
- 上位対応チームのアサインと役割分担
- 障害対応後の報告書の書式
以上のような項目を記載するとよいでしょう。
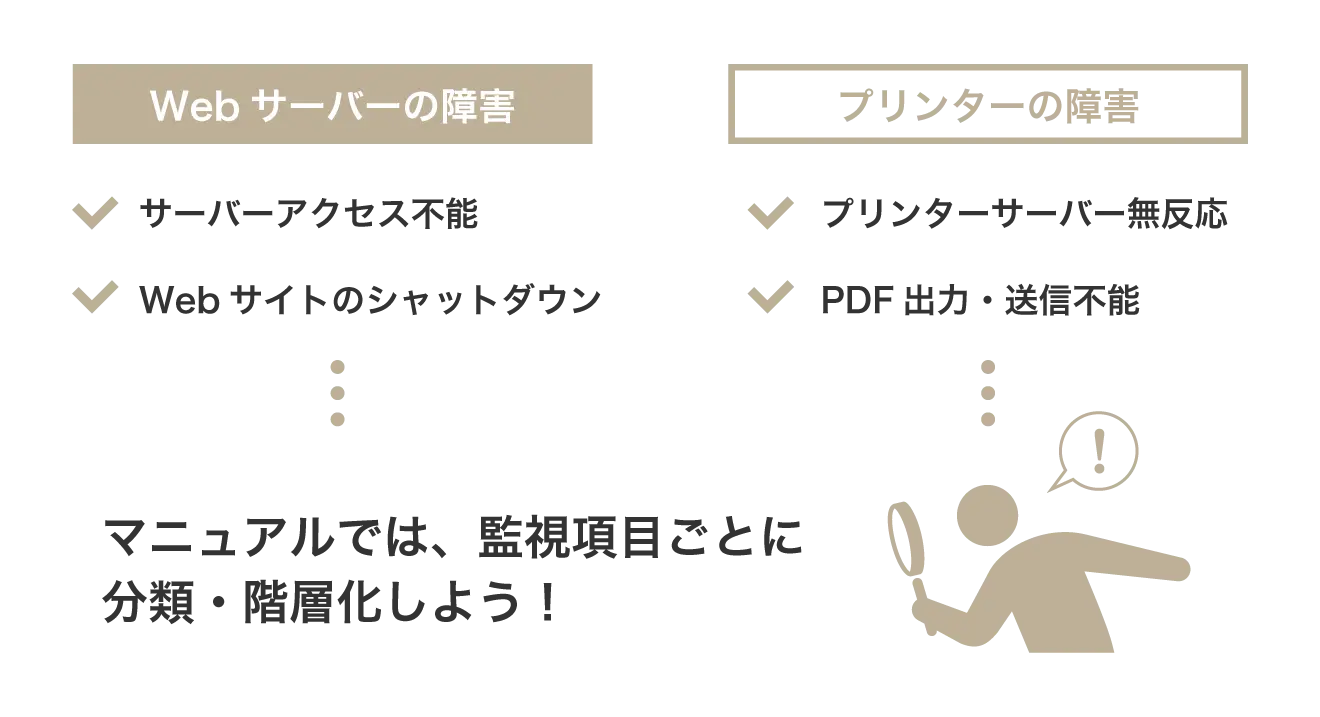
監視項目ごとに分類した上で、個別障害マニュアルの作成
システム障害発生の事例において、原因はひとつではありません。
例えば、ハードウェアの不調と人為的な操作ミスが重なったり、監視体制の甘さとソフトウェアのぜい弱性発現が重なってしまったり、というように多様な状況が原因となるのです。
しかし、システム障害の対応マニュアルにおいて、それらをあまり個々の状況として捉えないようにしましょう。わかりやすく分類した上で、初動の切り分けをはじめとした対応方針を明示する必要があります。
監視項目ごとの分類として、例えば「Webサーバーの障害」という親項目の中に「サーバーアクセス不能」を、「プリンターの障害」という親項目の中に「プリンターサーバードライバ無反応」の分類を設ける、というようにマニュアル上で階層化します。普段の定期チェックや障害発生時の対応においても、マニュアルを参照すれば適切な判断を迅速に行えるように準備しましょう。
マニュアル閲覧者からのフィードバックを反映
障害対応責任者やマニュアル整備担当者が、最適な形でマニュアルを作成できたと考えていたとしても、実際にそのマニュアルを活用する保守担当者や各部署の従業員にとってもわかりやすく、疑問点・不明点のないマニュアルでないといけません。
各部門の担当者や従業員に作成したマニュアルを確認してもらい、フィードバックを集め、定期的にマニュアルを改訂していくことも大切です。
「システム監視ツール(運用監視システム)」の有用性
障害の予兆を検知するには、システム監視ツールの活用が有効です。ここでは、システム監視ツールで実現できることや特徴を簡単に解説します。
システム監視について、関連記事をご用意しております。
▼システム監視とは? 目的やメリット、必要な監視項目をわかりやすく解説
システム監視ツール導入の目的・メリット
システム管理ツールは、システム障害の原因となる様々な予兆や事象を自動的に検出します。
システム監視ツールの目的は、システム障害の発生リスクを最小限に抑えることです。
いざ障害が発生してしまった場合にも、障害発生を迅速に検知し、あらかじめ設定したフローを基に関係者への自動通知を行います。
予兆の検出でリスクを最小限に抑えること、迅速な障害対応を行えることは、システム監視ツール導入の大きなメリットといえるのです。
システム監視ツールの監視範囲
システム監視ツールの監視範囲として、「インフラ監視」「サービス監視」に分類できます。これらについて、次項より紹介します。
インフラ監視
システム監視ツールのインフラ監視機能では、システムの安定稼働のためにハードウェアやネットワークの通信状況などを監視します。
例えば、リソース、Ping、ログ、パブリッククラウド、SNMP(Simple Network Management Protocol)の監視を行います。ITインフラ面の統合的な監視が可能です。
サービス監視
サービス監視機能では、主にサーバー上で動作するサービスソフトウェアの状況に関して、応答時間やリソース使用率、プロセスの状況や現在の可用性などを一元的に監視可能です。
サービス監視では、プログラムが正常に動作しているかに加え、ユーザーが問題なく利用できているか監視することも目的としています。
そのため、ブラウザからWebアプリにアクセスし表示内容やレスポンスなどをチェックする「外形監視」、サーバー上のプロセスの稼働状況を監視する「プロセス監視」が必要不可欠となります。
システム障害対策のご相談はテクバンへ
テクバンでは、お客様が運用するサーバーやネットワークを24時間365日体制でリモート監視する「Techvan Remote Center」を提供しております。現状の社内システム監視体制に課題を感じられている方、運用リソースに不安を感じられている方はぜひ、テクバンへご相談ください。
有人リモート監視の効果やメリットについては、こちらの事例もぜひご覧ください。
【事例】柔軟なメニューで実現できた。24時間365日、有人リモート監視で 情シスの負担軽減
様々な種類のシステム障害に平時から備えよう
障害の原因や事象、発生時の影響が多岐にわたるシステム障害については、平時から様々な観点で備えを行い、対応フローやマニュアルを整備しておく必要があります。
システム監視ツールを活用したり、監視サービスを提供しているベンダー企業に依頼したりすることで、システム障害への対策をより強固にできるでしょう。
自社での対応に限界を感じる際は、これらを検討してみることをおすすめします。
本記事でご紹介した内容が、システム障害の対応フロー策定にお役立てできれば幸いです。









